|
0.5.1
|
|
0.5.1
|
We are going to postulate the following things about the Kalman filter
For any multivariate Gaussian state of dimension  , we can express its Gaussian probability density function as
, we can express its Gaussian probability density function as



The basic idea of the Kalman filter is that both, prediction and update are represented by linear function/transformations between the state-space respectively the observation space.

The following table summarizes the meaning of these variables.
| Variable | Meaning |
|---|---|
 |  state transition matrix, which describes the linear relation between the state at time state transition matrix, which describes the linear relation between the state at time  and and  . . |
 | (linear) control-input model which is applied to the control vector  (note: in many cases ) is zero, in particular when we deal with an error-state Kalman filter (note: in many cases ) is zero, in particular when we deal with an error-state Kalman filter |
 | observation model, which linearly maps the state space into the observation space |
 | process noise, which is assumed to be drawn from a zero mean multivariate normal distribution, with covariance  so that so that  |
 | observation noise, which is assumed to be zero mean Gaussian white noise with covariance  so that so that  |
Considering now that we have a linear prediction model described above, one can compute the Gaussian probability density function after predication as

In a similar way, one can derive the Gaussian probability density function after after making noisy observations as

.
Assumption (not proven here): Prediction and update of states with underlying Gaussian distributions lead to Gaussian distributions again. Thus, one can make use of Bayes' Theorem which states that prediction can be understood as convolution of the prior probability density function (PDF), here called "belief"  with the PDF of the prediction. This means, prediction can be understood as
with the PDF of the prediction. This means, prediction can be understood as

where superscript  indicates that we obtain a predicted belief from this equation. Moreover, we know from Bayes' Theorem that observation of a state is equal to multiplication of the PDF of the (predicted belief) with PDF of the observation. This means
indicates that we obtain a predicted belief from this equation. Moreover, we know from Bayes' Theorem that observation of a state is equal to multiplication of the PDF of the (predicted belief) with PDF of the observation. This means

where superscript  indicates that we obtain a new belief after making an observation which depends on the state. The factor
indicates that we obtain a new belief after making an observation which depends on the state. The factor  makes sure that the obtained Gaussian fulfills the normalization criteria, i.e. its hyper-volume is equal to
makes sure that the obtained Gaussian fulfills the normalization criteria, i.e. its hyper-volume is equal to  .
.
Putting the PDF for prediction into Bayes' Theorem we obtain

where  represents the expectation value of the belief before prediction. This can be formally written as
represents the expectation value of the belief before prediction. This can be formally written as


The basic idea is now to split  so that it contains two terms, from which only one depends on
so that it contains two terms, from which only one depends on  , i.e.
, i.e.



since the term  can be extracted from the integral as it does not depend on
can be extracted from the integral as it does not depend on  . Moreover, as we know that the outcome from this function must be a Gaussian again, we can write this as
. Moreover, as we know that the outcome from this function must be a Gaussian again, we can write this as

The Gaussian probability density function reaches its highest value for its the expectation value. Thus, if we differentiate the exponent in the Gaussian PDF and set the result equal to zero we find its expectation value. Thus, we find

![\begin{equation} \label{eq:eq-Bayes-prediction09}
\boldsymbol{\Phi}^T_t\boldsymbol{Q}^{-1}_t(\boldsymbol{x}_t-\boldsymbol{\Phi}_t\boldsymbol{x}_{t-1}-\boldsymbol{B}_t\boldsymbol{u}_t)=\boldsymbol{\Sigma}^{-1}_{t-1}(\boldsymbol{x}_{t-1}-\boldsymbol{\mu}_{t-1})\\[2mm]
\end{equation}](form_533.svg)
This can be further re-arranged to

Moreover, we know that double differentiation of the exponent provides us with the information matrix / weight matrix, i.e. the inverse of the covariance matrix. Thus, we obtain

which we can use to find an alternative notation for the findings before

Therefore we can re-write the exponent as

Now we are able to compute the term which only one depends on



Based on this, we can differentiate w.r.t. to in order to obtain the expectation value, i.e.


![\begin{equation} \label{eq:eq-Bayes-prediction19}
\boldsymbol{Q}^{-1}_t-\boldsymbol{Q}^{-1}_t\boldsymbol{\Phi}_t(\boldsymbol{\Phi}^T_t\boldsymbol{Q}^{-1}_t\boldsymbol{\Phi}_t+\boldsymbol{\Sigma}^{-1}_{t-1})^{-1} \boldsymbol{\Phi}^T_t\boldsymbol{Q}^{-1}_t=(\boldsymbol{Q}_t+\boldsymbol{\Phi}_t\boldsymbol{\Sigma}_{t-1}\boldsymbol{\Phi}^T_t)^{-1}\\[6mm]
\end{equation}](form_543.svg)
We can further simplify and obtain



We also find the covariance after prediction, from the second derivative, i.e.

Thus, in summary we could prove that the prediction step in the linear Kalman filter turns out to be rather simple, ie.

where the superscript  indicates, that we deal with the predicted state and the covariance, respectively.
indicates, that we deal with the predicted state and the covariance, respectively.
As for the update step (we will call it ''update'' hereafter although one might also see it as ''correction'' step), we start with Bayes' Theorem that tell us the conditional likelihood in case we observe an uncertain state. This can be written as

where  is a factor that normalizes the product on the right side, so that a proper PDF is obtained. Knowing know that everything is Gaussian, including the term on the left side, we can write above's equation as
is a factor that normalizes the product on the right side, so that a proper PDF is obtained. Knowing know that everything is Gaussian, including the term on the left side, we can write above's equation as


Like before, we can find the expectation value of this function, by differentiating the term  and setting the result equal to zero.This means
and setting the result equal to zero.This means


The second derivative of provides us the inverse of the covariance matrix, i.e.

![\begin{equation} \label{eq:eq-Bayes-update07}
\boldsymbol{\Sigma}_t=(\boldsymbol{H}^T_t\boldsymbol{R}^{-1}_t\boldsymbol{H}_t+(\boldsymbol{\Sigma}_t^{-})^{-1})^{-1}\\[2mm] % 3.37
\end{equation}](form_558.svg)
The equation that hold the expectation value can be re-written to

which in turn allows us to identify


, or by using the so-called Kalman gain

we obtain a very simple rule how the update has to be computed

However, we might want a more straightforward expression for the Kalman gain, that contains only the predicted covariance and not the one after making observations. Thus, we do a series of mathematical tricks and obtain

We can also find an easier expression for the updated covariance matrix, if we use a matrix lemma and reformulate

![\begin{eqnarray} \label{eq:eq-Bayes-update15}
\boldsymbol{\Sigma}_t&=(\boldsymbol{H}^T_t\boldsymbol{R}^{-1}_t\boldsymbol{H}_t+(\boldsymbol{\Sigma}_t^{-})^{-1})^{-1}\\
&=\boldsymbol{\Sigma}_t^{-}-\boldsymbol{\Sigma}_t^{-}\boldsymbol{H}^T_t(\boldsymbol{R}_t+\boldsymbol{H}_t\boldsymbol{\Sigma}_t^{-}\boldsymbol{H}^T_t)^{-1}\boldsymbol{H}_t\boldsymbol{\Sigma}_t^{-}\\
&=[\boldsymbol{I}-\underset{=\boldsymbol{K}_t}{\underbrace{\boldsymbol{\Sigma}_t^{-}\boldsymbol{H}^T_t(\boldsymbol{R}_t+\boldsymbol{H}_t\boldsymbol{\Sigma}_t^{-}\boldsymbol{H}^T_t)^{-1}}}\boldsymbol{H}_t]\boldsymbol{\Sigma}_t^{-}\\
&=(\boldsymbol{I}-\boldsymbol{K}_t\boldsymbol{H}_t)\boldsymbol{\Sigma}_t^{-}
\end{eqnarray}](form_566.svg)
Putting everything together we find for the update step the following very simple rules

Assuming that we sequentially make predictions o

and update the state and its covariance

we can use the Kalman filter as the optimal Bayesian estimator assuming that all uncertainties are modeled by multivariate Gaussians. This is visualized in the following figure as well.
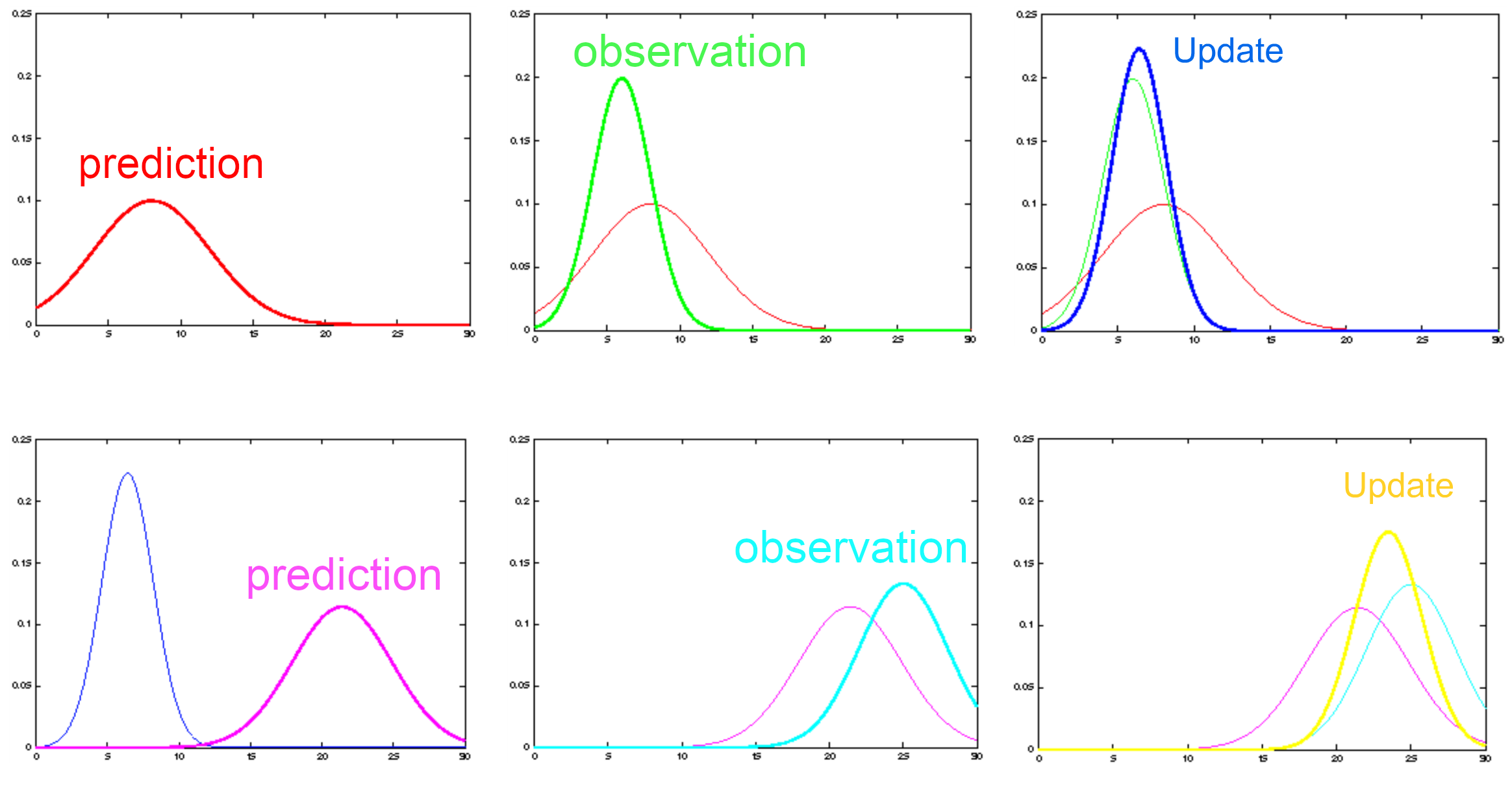
There are many reasons, why the covariance matrix of Kalman Filter can become singular. Mostly very small variances of the process noise or measurement noise, large differences in the magnitude of the state parameters or generally weakly conditions observation conditions, lead to singular or close-to singular matrices. In order to overcome or slightly improve such conditions, it is possible to describe the Kalman filter in its so-called square root form. Therefore it is important to understand how the square root of a matrix can be computed. Basically there are the following two possibilites for defining the square root of a matrix 

Either of the two definitions can be achieved by the following three matrix decomposition methods




 which returns us the
which returns us the  matrix of the QR decomposition, we can write
matrix of the QR decomposition, we can write

represents

If we start with the prediction step

We can write this (assuming we have Cholesky decomposed the covariance matrix and the process noise matrix) as

This relation can also be written in the form

Thus, as shown before, we can use the QR decomposition to obtain

The update step is a little bit more complicated, as we need to compute the Kalman gain by the help of the innovation matrix. Thus, the latter is QR decomposed first

where  is the square root of the measurement noise matrix (note: since this matrix is usually a diagonal matrix this square root of it can be compute straightforward without Cholesky decomposition) One can now compute the Kalman gain as
is the square root of the measurement noise matrix (note: since this matrix is usually a diagonal matrix this square root of it can be compute straightforward without Cholesky decomposition) One can now compute the Kalman gain as

With that one can compute the updated (square root) covariance matrix as

Prediction and update of the state works like in the standard Kalman filter, since all necessary matrices are available anyway.
Note: While the square root form of the Kalman filter provides more numerical stability, and better balancing of the matrices, this advantage is lost at the point where the user need to back-compute the covariances matrices from their square root equivalent.