|
0.5.1
|
|
0.5.1
|
INSTINCT is a PNT software developed at the Institute of Navigation (INS), University of Stuttgart, Germany. It allows Flow-Based Programming for real-time operation with different sensors, or post-processing using its own simulators and file readers.
INSTINCT can be obtained via GitHub where a installation guide is also provided. If you encounter any issues whit the installation, refer to the discussions on GitHub and use the Q&A section.
If you are using INSTINCT for the first time or search for a guide for a specific Node or feature, refer to the User Manual.
Developers who are looking for a more detailed description should refer to Developer Manual. This includes information regarding the internal processes and formulas as well as the source codes.
To contact the Institute of Navigation, Stuttgart related to INSTINCT, we recommend the Q&A-section on GitHub stated above in the Installation. Other then that, a mailing list is available.
To contact the Institute for all other purposes, the INS University Homepage will provide additional contact information and address.
INSTINCT by the Institute of Navigation of the University of Stuttgart, Germany, is subject to the terms of the Mozilla Public License, v. 2.0. A copy can be found at https://mozilla.org/MPL/2.0/.
If you are using INSTINCT for academic work, please use the following citation:
If you are interested in papers and publications that are related to INSTINCT, the following list provides a selection of such:
The following sections are drafted from the paper "Flow-Based Programming for Real-Time Multi-Sensor Data Fusion," above, published by the Institute of Navigation, University Stuttgart, regarding the INSTINCT toolkit.
Flow-based programming (FBP), which was first discussed by [33], was developed with the purpose to overcome limitations in "von Neumann" hardware [45] and with the goal of exploiting massive parallelism [26]. The main idea by Morrison was that data-processing tasks are separated into modules, which can communicate among each other with the help of data elements that are passed through queues. In the background, a scheduler is used to trigger the calculations in each module depending on the availability of data elements, service requests by modules and external events [33]. The flow of the data can be displayed as a directed graph and therefore is eponymous for the name of the approach "dataflow programming".
The smaller the workload that each module has to handle, the better FPB benefits from parallel computing capabilities of the hardware. Originally, as described by [45], it was intended to have specialized dataflow hardware architecture. Consequently, dataflow programming languages were invented [1],[55]. However, with the progress of multiprocessing and multithreading capabilities in the last decades, FBP can also be applied to "von Neumann" architecture-based computer systems. Besides performance benefits from parallelism, FBP also has other advantages. Because each module acts as a black box, which resembles the way object-oriented programming abstracts its functionality, one does not have to know every detail of its implementation, but only needs to understand its input and output data elements. This leads to higher and low-latent productivity of new developers [33]. Furthermore, [34] presented empirical evidence that FBP reduces development times and therefore reduces programming costs. These results are further confirmed by [31] who also claim that FBP increases code reuse and maintainability.
Conventional software usually follows a hard-coded processing chain and has little adaptability when sensors change, algorithms are exchanged, or the software is needed to work in both real-time and post-processing environments. FBP, however, allows more flexibility because modules with the same inputs and outputs, like a sensor or a data file reader, can be exchanged with each other. This provides the possibility to develop the program logic and algorithms in post-processing and then exchange only the input modules in order to deploy the program onto a test device with sensors.
More recent work from [39] states that FBP can also exceed service-oriented architectures (SOA) [49] in terms of code complexity and code size. The initial effort to write an application, which can define and manipulate the dataflow graph, is bigger, but the data discovery and processing tasks become simpler. Moreover, there are frameworks available that might serve this purpose, such as Google Dataflow [29], Kubeflow [6], Apache NiFi [2], flowpipe [44] or Simulink [32]. However, these existing frameworks introduce problems with licensing or are not suitable to be executed on low-cost hardware such as single-board computers, which are used on mobile PNT platforms.
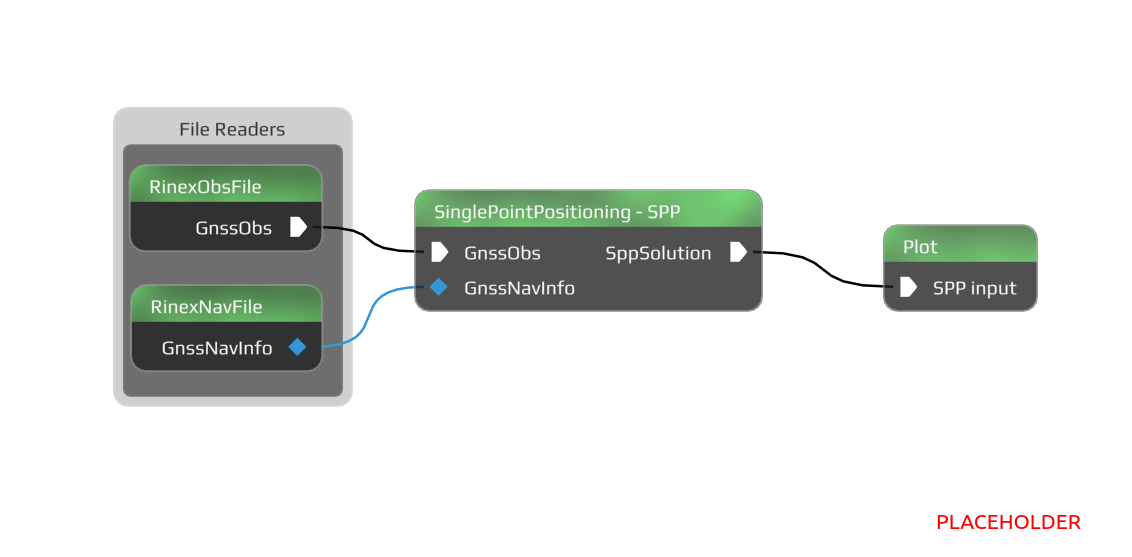
INSTINCT follows the flow-based programming paradigm but uses a different notation. Modules are called "nodes" but serve the same purpose on encapsuling functionality. A difference however is, that larger chunks of functionality are bundled in each node. For example, the single point positioning (SPP) algorithm that calculates positions and velocities from GNSS observations is represented by a single node despite consisting of multiple data processing steps. This obviously limits the possibility of parallelizing calculations but is a needed trade-off between simplicity of the dataflow and performance. Furthermore, on hardware architectures which are not designed for parallelism it does not make sense to split an application into thousands of threads as the overhead from passing the data and thread management becomes significant.
Like the modules in FBP, nodes can pass data elements to each other via so-called input and output "pins". However, in INSTINCT, nodes can have multiple in- and output pins, whereas in the original concept by [33] only one of each was foreseen. Data objects, which are supposed to flow between nodes, have to inherit from a common class that enables the required functionality. This makes it easy to define new custom node data classes tailored to the data that should be passed. Using specialized classes as node data does not create unnecessary overhead as it is done in other software implementing the FBP paradigm, e.g. Node-RED [38], where JSON objects are used. It also enables the program to check if connections between nodes, so-called "links", are valid or if the data types differ and the connection should be refused. Therefore, even users who do not know the software cannot configure invalid dataflows. The base node data class also provides a way to set a timestamp for each object that enables the scheduler to trigger nodes in correct order. To avoid unnecessary copies while passing data, the data is passed as a reference to the data object, or more specifically as a shared C++ pointer [24]. Shared pointers have the advantage, that they automatically keep track of how often they are referenced. When no reference exists anymore, they release their reserved memory preventing any possible memory leaks that could occur with normal pointers. This makes it possible for nodes to keep the data as long as it is needed without the risk that it is set invalid. Moreover, references are passed as non-mutable variables because the same data can flow into multiple nodes. This could lead to data races and undefined behavior if nodes modify the objects.
Beside data flowing between nodes, the FBP paradigm was extended in INSTINCT through object pins that provide access to C++ objects living inside the nodes. This can be used as an interface to provide access to data that either does not change or changes very slowly with time and whose ownership should stay within the source node. An example for such data would be navigation GNSS data which is read from a file at the start of the execution or is slowly collected inside a node from a GNSS receiver.
Last updated: 2025-07-18